hbase 简介
随便看看,别要求太过分
HBase 简介
HBase 是什么
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://HBase.apache.org
-- 2006年Google发表BigTable白皮书
-- 2006年开始开发HBase
-- 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目
-- 2010年HBase成为Apache顶级项目
-- 现在很多公司二次开发出了很多发行版本,你也开始使用了。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase 特性
海量存储
HBase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与HBase的极易扩展性息息相关。正式因为HBase良好的扩展性,才为海量数据的存储提供了便利
列式存储
这里的列式存储其实说的是列族存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定
极易扩展
HBase的扩展性主要体现在两个方面,一个是基于上层处理能力(Region Server)的扩展,一个是基于存储的扩展(HDFS)。通过横向添加Region Sever的机器,进行水平扩展,提升HBase上层的处理能力,提升HBase服务更多Region的能力。备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升HBase的数据存储能力和提升后端存储的读写能力
高并发
由于目前大部分使用HBase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百MS之间。这里说的高并发,主要是在并发的情况下,HBase的单个IO延迟下降并不多。能获得高并发、低延迟的服务
稀疏
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的
数据的多版本
HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
数据类型单一
所有的数据在HBase中是以字节数组进行存储
HBase 数据模型
HBase是一个NoSQL数据库,它通过一个四维数据模型定义数据:
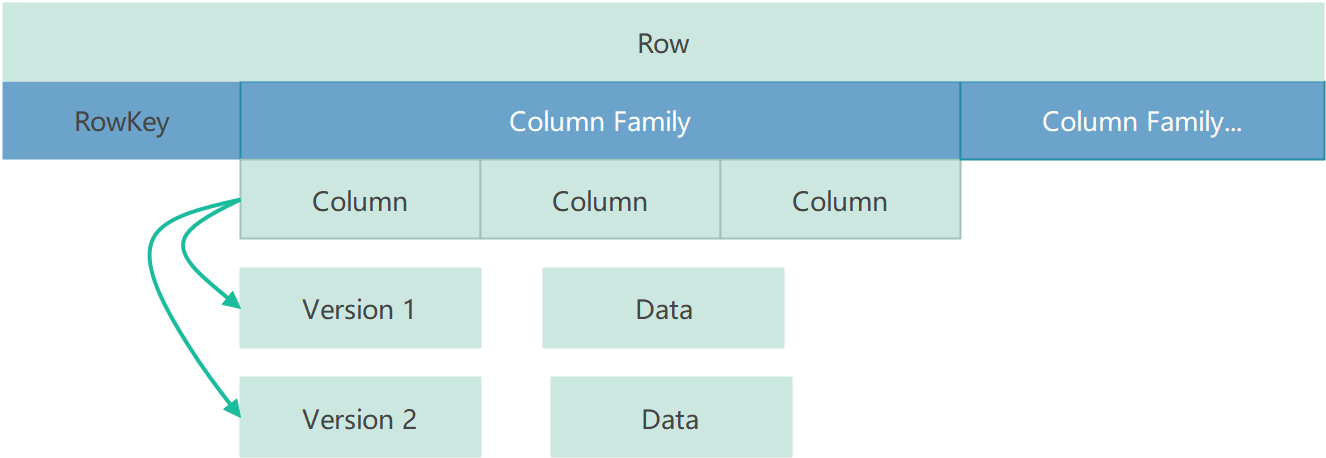
RowKey
HBase中的每行数据都必须拥有一个唯一的行键,它类似于关系型数据库中的主键
Column Family
HBase中的每个列都归属于一个列簇,它类似于子表的概念。一个列簇对应一个MemStore对象
Column
HBase用列来定义数据属性字段,和关系型数据库中的表字段类似
Version
HBase中的数据是有版本概念的,每次新增或者修改数据都会产生一个新的版本
HBase 命名空间
命名空间结构:
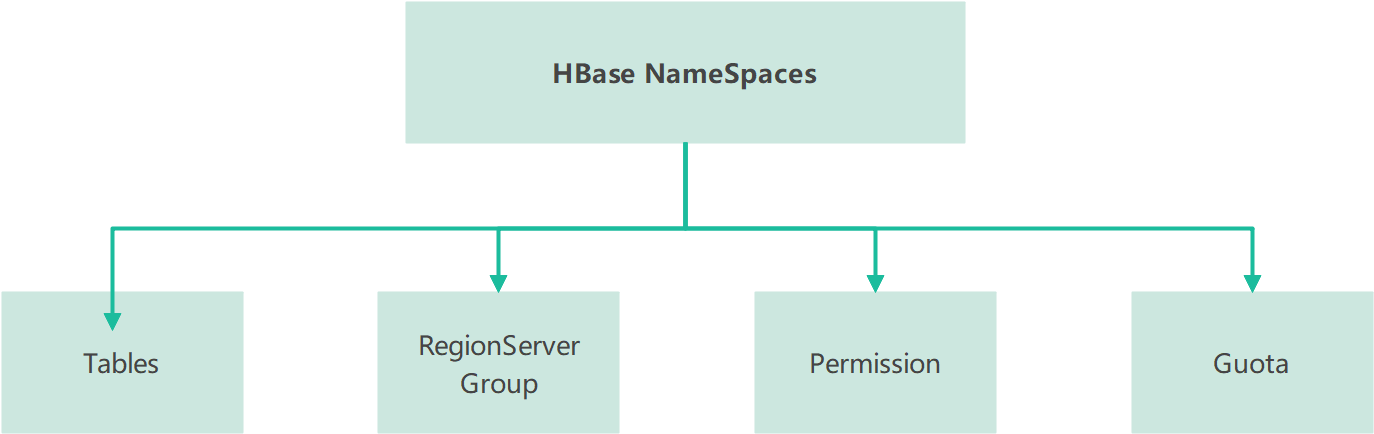
Table
表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在default默认的命名空间中。
RegionServer group
一个命名空间包含了默认的RegionServer Group。
Permission
权限,命名空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
Quota
限额,可以强制一个命名空间可包含的region的数量。
HBase 逻辑架构
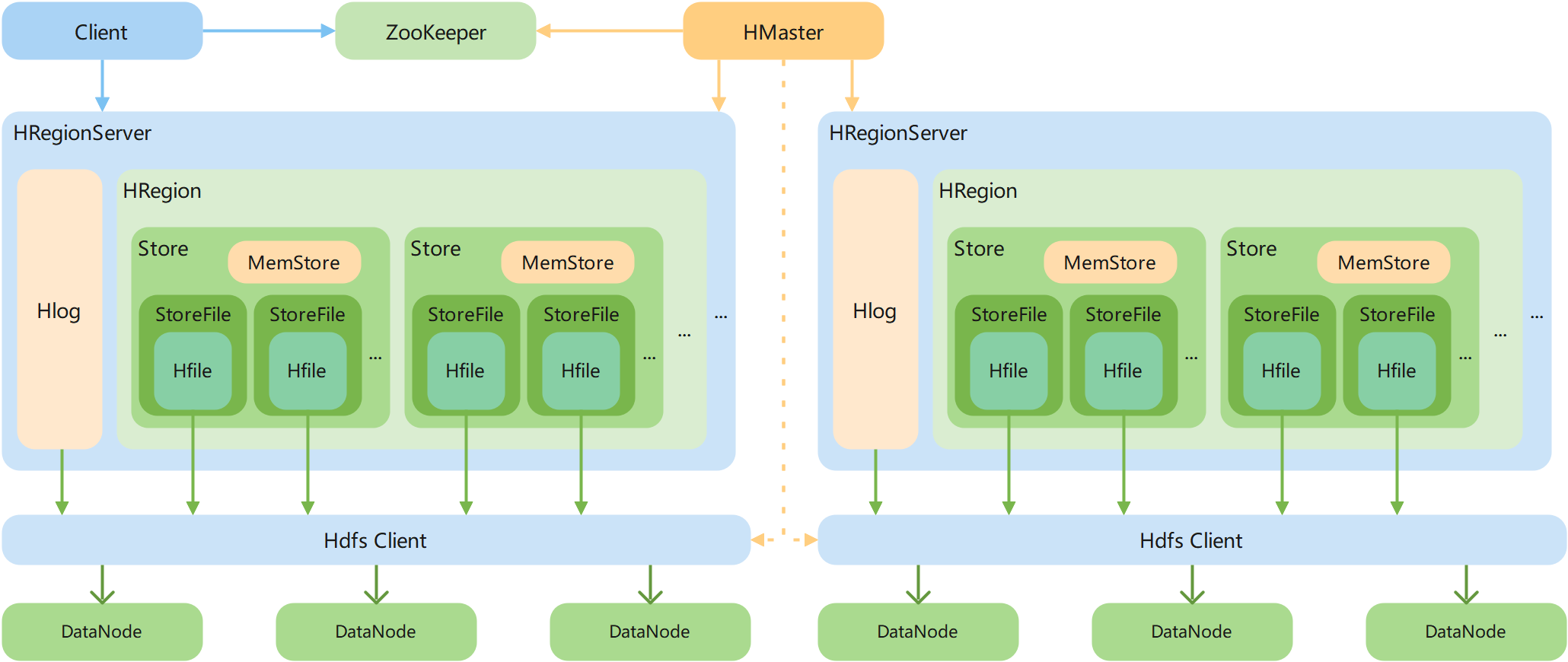
Client
Client包含了访问HBase的接口,另外Client还维护了对应的cache来加速HBase的访问,比如cache的.META.元数据的信息。
Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。
Master
Master 是所有 Region Server 的管理者,其实现类为 HMaster,主要作用如下:
- 为RegionServer分配Region
- 维护整个集群的负载均衡
- 维护集群的元数据信息
- 发现失效的Region,并将失效的Region分配到正常的RegionServer上
- 当RegionSever失效的时候,协调对应Hlog的拆分
对于表的操作:create, delete, alter
对于 RegionServer的操作:分配 regions到每个RegionServer,监控每个 RegionServer的状态,负载均衡和故障转移。
Region Server
Region Server 为 Region 的管理者,其实现类为 HRegionServer,主要作用如下:
- 管理master为其分配的Region
- 处理来自客户端的读写请求
- 负责和底层HDFS的交互,存储数据到HDFS
- 负责Region变大以后的拆分
- 负责Storefile的合并工作
对于数据的操作:get, put, delete;
对于 Region 的操作:splitRegion、compactRegion。
Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有的。
MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
Hlog(WAL)
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中,会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。
HBase 写流程
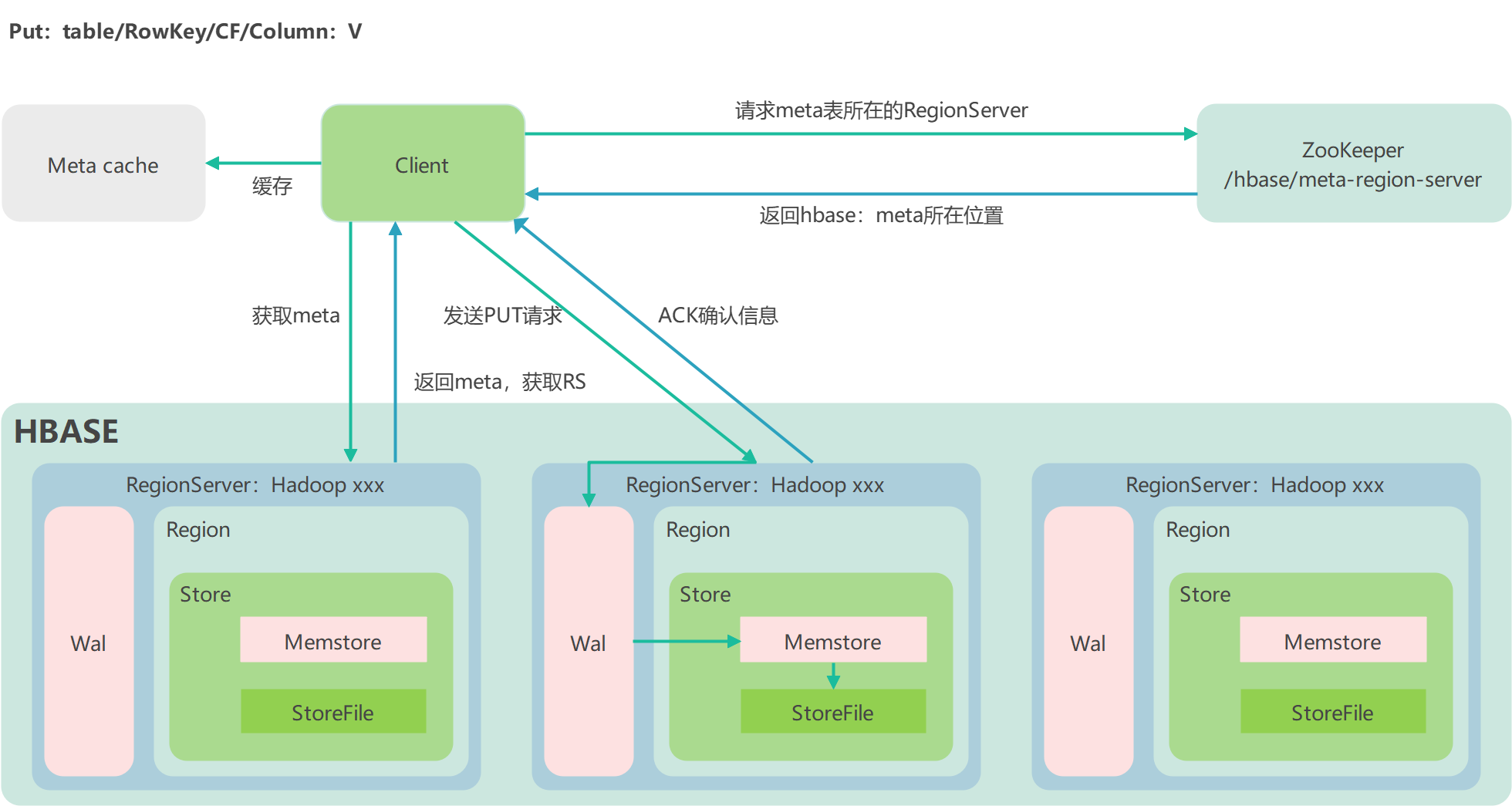
步骤一:
Client 先访问 zookeeper,获取 HBase:meta 表位于哪个 Region Server
步骤二:
访问对应的 Region Server,获取 HBase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问
步骤三:
与目标 Region Server 进行通讯
步骤四:
将数据顺序写入(追加)到 WAL
步骤五:
将数据写入对应的 MemStore,数据会在 MemStore 进行排序
步骤六:
向客户端发送 ack
步骤七:
等达到 MemStore 的刷写时机后,将数据刷写到 HFile
HBase 读流程
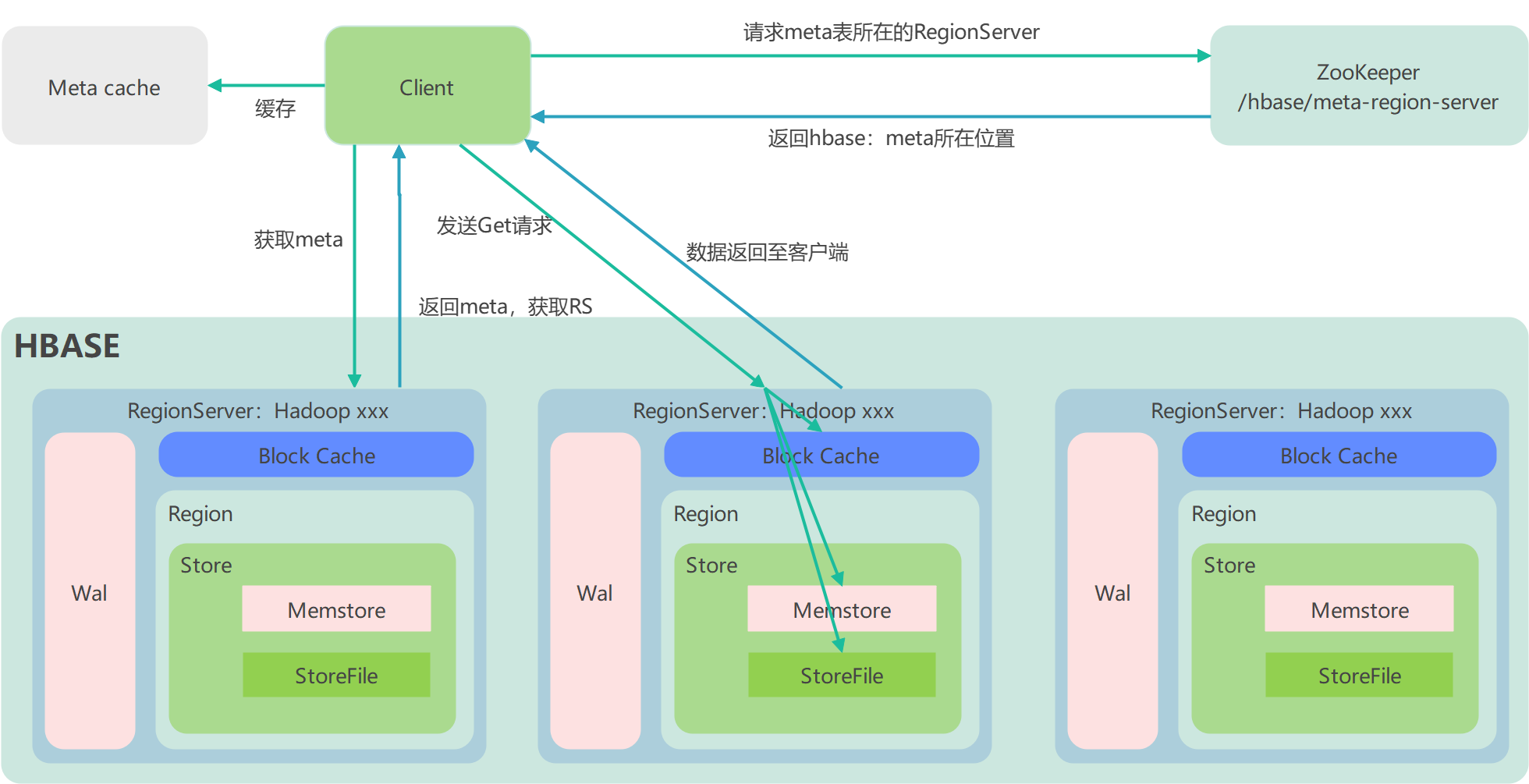
步骤一:
Client 先访问 zookeeper,获取 HBase:meta 表位于哪个 Region Server
步骤二:
访问对应的 Region Server,获取 HBase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问
步骤三:
与目标 Region Server 进行通讯
步骤四:
分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)
步骤五:
将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache
步骤六:
将合并后的最终结果返回给客户端
HBase Flush
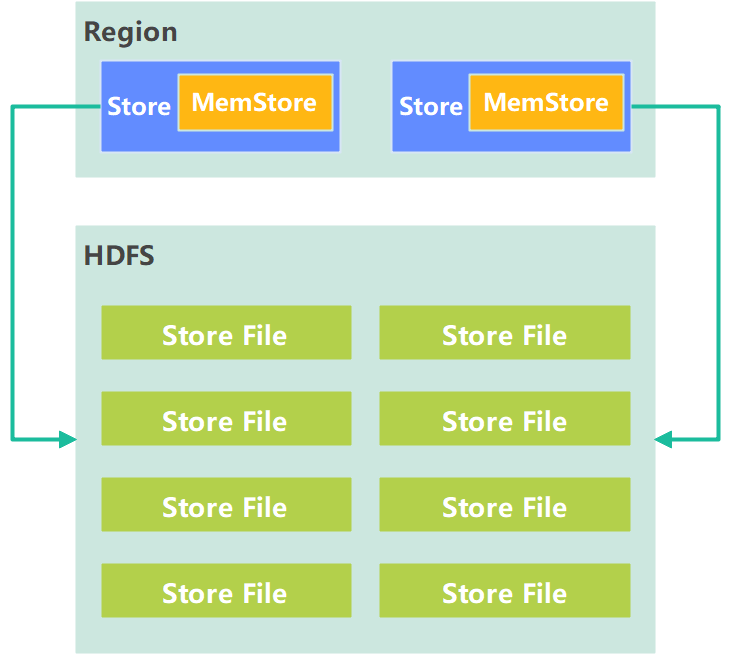
- 当某个 MemStore 的大小达到了对应值,其所在 region 的所有 MemStore 都会刷写。
hbase.hregion.memstore.flush.size(默认值 128M)
- 当 MemStore 的大小达到对应值时,会阻止继续往该 MemStore 写数据。
hbase.hregion.memstore.flush.size(默认值 128M)
* hbase.hregion.memstore.block.multiplier(默认值 4)
- 当 region server 中 MemStore 的总大小达到对应值,region 会按照其所有 MemStore 的大小顺序(由大到小)依次进行刷写。直到 region server中所有 MemStore 的总大小减小到相应值以下
java_heapsize
* hbase.regionserver.global.memstore.size(默认值 0.4)
* hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95)
- 当 region server 中 MemStore 的总大小达到时,会阻止继续往所有的 MemStore 写数据。
java_heapsize
* hbase.regionserver.global.memstore.size(默认值 0.4)
- 到达自动刷写的时间,也会触发 MemStore flush。自动刷新的时间间隔由该属性进行配置
hbase.regionserver.optionalcacheflushinterval(默认 1 小时)
HBase Compact
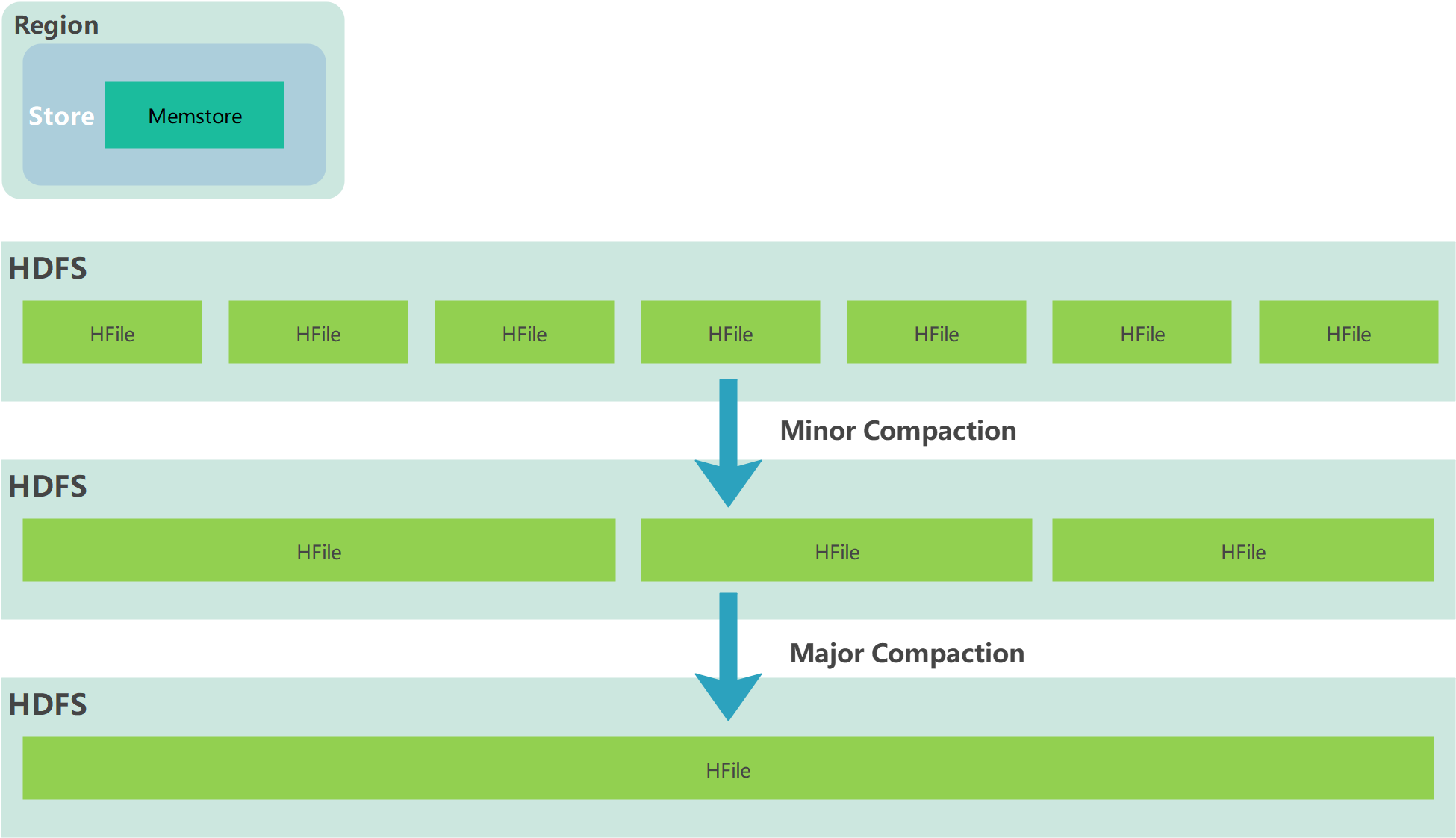
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction:
- Minor Compaction会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
- Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。
HBase Split
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
HBase的Region Split策略一共有以下几种:
1)ConstantSizeRegionSplitPolicy
0.94版本前默认切分策略
当region大小大于某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
但是在生产线上这种切分策略却有相当大的弊端:切分策略对于大表和小表没有明显的区分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事。如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
2)IncreasingToUpperBoundRegionSplitPolicy
0.94版本~2.0版本默认切分策略
切分策略稍微有点复杂,总体看和ConstantSizeRegionSplitPolicy思路相同,一个region大小大于设置阈值就会触发切分。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.
region split的计算公式是:
regioncount^3 * 128M * 2,当region达到该size的时候进行split
例如:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了
3)SteppingSplitPolicy
2.0版本默认切分策略
这种切分策略的切分阈值又发生了变化,相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些,依然和待分裂region所属表在当前regionserver上的region个数有关系,如果region个数等于1,切分阈值为flush size * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
4)KeyPrefixRegionSplitPolicy
根据rowKey的前缀对数据进行分组,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在进行region split的时候会分到相同的region中。
5)DelimitedKeyPrefixRegionSplitPolicy
保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
6)DisabledRegionSplitPolicy 不启用自动拆分, 需要指定手动拆分
Region拆分策略可以全局统一配置,也可以为单独的表指定拆分策略:
1)通过hbase-site.xml全局统一配置(对hbase所有表生效)
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>
2)通过Java API为单独的表指定Region拆分策略
HTableDescriptor tableDesc = new HTableDescriptor("test1");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY,
IncreasingToUpperBoundRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
3)通过HBase Shell为单个表指定Region拆分策略
hbase> create 'test2', {METADATA => {'SPLIT_POLICY' =>
'org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy'}},{NAME => 'cf1'}
Hbase Pre-Splitting
为什么要预分区(Pre-Splitting)
当一个table刚被创建的时候,Hbase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于比较空闲的状态。解决这个问题可以用Pre-Splitting,在创建table的时候就配置好,生成多个region。
增加数据读写效率
负载均衡,防止数据倾斜
方便集群容灾调度region
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维
如何进行预分区(Pre-Splitting)
1)手动设定预分区
create 'student','info1','info2',SPLITS => ['1000','2000','3000']
2)按照文件内容预分区
文件内容:split.txt
1000
2000
3000
命令行:
create 'student','info1','info2',SPLITS_FILE => '/root/hbase/split.txt'
3)生成16进制序列预分区
create 'student','info1','info2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
4)根据API分区
public class HBaseConnect {
public static void main(String[] args) throws IOException {
// 1.获取配置类
Configuration conf = HBaseConfiguration.create();
// 2.给配置类添加配置
conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");
// 3.获取连接
Connection connection = ConnectionFactory.createConnection(conf);
// 4.获取admin
Admin admin = connection.getAdmin();
// 5.获取descriptor的builder
TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf("bigdata", "group4"));
// 6. 添加列族
builder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info")).build());
// 7.创建对应的切分
byte[][] splits = new byte[3][];
splits[0] = Bytes.toBytes("aaaa");
splits[1] = Bytes.toBytes("bbbb");
splits[2] = Bytes.toBytes("cccc");
// 8.创建表
admin.createTable(builder.build(),splits);
// 9.关闭资源
admin.close();
connection.close();
}
}
HBase RowKey
HBase所谓的三维有序存储的三维是指:rowkey(行主键),column key(columnFamily+qualifier),timestamp(时间戳)三部分组成的三维有序存储。
rowkey是行的主键,而且hbase只能用单个rowkey,或者一个rowkey的范围即scan来查找数据。所以 rowkey的设计是至关重要的。
1)RowKey唯一原则
必须在设计上保证其唯一性。由于在HBase中数据存储是Key-Value形式,若HBase中同一表插入相同Rowkey,则原先的数据会被覆盖掉(如果表的version设置为1的话),所以务必保证Rowkey的唯一性
2)RowKey排序原则
HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点
3)RowKey长度原则
RowKey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。建议越短越好,不要超过16个字节,设计过长会降低memstore内存的利用率和HFile存储数据的效率
4)RowKey散列原则
Rowkey应均匀的分布在各个HBase节点上。拿常见的时间戳举例,假如Rowkey是按系统时间戳的方式递增,Rowkey的第一部分如果是时间戳信息的话将造成所有新数据都在一个RegionServer上堆积的热点现象,也就是通常说的Region热点问题, 热点发生在大量的client直接访问集中在个别RegionServer上(访问可能是读,写或者其他操作),导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用,常见的是发生jvm full gc或者显示region too busy异常情况,当然这也会影响同一个RegionServer上的其他Region。
- 热点产生的原因:
检索habse的记录首先要通过row key来定位数据行。当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多、负载过大,而其他region server负载却很小,就造成了“热点”现象。
- 热点的解决方案:
预分区
预分区的目的让表的数据可以均衡的分散在集群中,而不是默认只有一个region分布在集群的一个节点上。
Salt加盐
Salt是将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标
4个region,[,a),[a,b),[b,c),[c,] 原始数据 abc1 abc2 abc3 加盐后的rowkey: a-abc1 b-abc2 c-abc3哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
原始数据: abc1 abc2 abc3 哈希: md5(abc1) = 92231......9223-abc1 md5(abc2) = 32a13......32a1-abc2 md5(abc3) = 452b1......452b-abc3反转
反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
- HBase 是什么
- HBase 特性
- HBase 数据模型
- HBase 命名空间
- HBase 逻辑架构
- HBase 写流程
- HBase 读流程
- HBase Flush
- HBase Compact
- HBase Split
- Hbase Pre-Splitting
- HBase RowKey