Hive 基本概念
随便看看,别要求太过分
Hive 基本概念
本文简单介绍下 Hive 的基本概念以及 Hive 的基本架构,推荐读者为 Hive 数据库的使用者。
Hive 简介
Hive 基本概念
Apache Hive™ 数据仓库软件可以方便地读取、写入和管理分布式存储中的大型数据集,并使用 SQL 语法进行查询。
Hive 基本特性
Apache Hive™ 构建在 Apache Hadoop™ 之上,并提供以下特性:
- 可以通过 SQL 轻松访问数据的工具,从而支持 ETL(提取/转换/加载)、报告和数据分析等数据仓库任务。
- 一种将结构强加于各类数据格式的机制
- 访问直接存储在 Apache HDFS™ 或其他数据存储系统如 Apache HBase™ 中的文件
- 通过 Apache Tez™、Apache Spark™ 或 MapReduce 执行查询
- 通过 HPL-SQL 进行编程
- 通过 Hive LLAP、Apache YARN 和 Apache Slider 进行次秒查询检索。
Hive 其他特性
Apache Hive™ 其他特性:
Hive 提供标准的 SQL 功能,包括 SQL 标准:SQL:2003、SQL:2011及SQL:2016的多数特性。
Hive SQL 还可以通过用户定义函数(UDFs)、用户定义聚合(UDAFs)以及用户定义表函数(UDTFs),使用用户的自定义代码进行扩展。
Hive 的数据存储格式不是单一的一种类型,Hive 自带 CSV/TSV(分隔符为逗号和制表符)的文本类型、Apache Parquet™ 类型、Apache ORC™ 类型以及其他格式类型。Hive同时也允许用户使用其他格式的连接器来扩展 Hive 的存储格式。详细信息请参见《开发者指南》中的 File Formats 和 Hive SerDe 。
Hive 不是为在线事务处理(OLTP)工作负载而设计的。它最适合用于传统的数据仓库(OLAP)任务。
Hive 具备高伸缩性(通过向 Hadoop 集群动态添加更多机器来扩展性能)、可扩展性、高容错性、松耦合性。
Hive 的组件包括 HCatalog 和 WebHCat :
- HCatalog 提供了一个统一的元数据服务,允许不同的工具如 Pig、MapReduce 等通过 HCatalog 直接访问存储在 HDFS 上的底层文件。
- WebHCat 提供了一个服务,可以使用它来运行 Hadoop MapReduce(或YARN),Pig,Hive作业。也可以使用 HTTP (Rest)接口执行 Hive 元数据操作。
数据仓库概念
数据仓库(Data Warehouse)是⼀个⾯向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反应历史变化(Time Variant)的数据集合,⽤于⽀持管理决策。
数据仓库体系结构通常含四个层次:数据源、数据存储和管理、数据服务、数据应⽤。
数据源:是数据仓库的数据来源,含外部数据、现有业务系统和⽂档资料等;
数据集成:完成数据的抽取、清洗、转换和加载任务,数据源中的数据采⽤ETL(Extract-Transform-Load)⼯具以固定的周期加载到数据仓库中。
数据存储和管理:此层次主要涉及对数据的存储和管理,含数据仓库、数据集市、数据仓库检测、运⾏与维护⼯具和元数据管理等。
数据服务:为前端和应⽤提供数据服务,可直接从数据仓库中获取数据供前端应⽤使⽤,也可通过OLAP(OnLine Analytical Processing,联机分析处理)服务器为前端应⽤提供负责的数据服务。
数据应⽤:此层次直接⾯向⽤户,含数据查询⼯具、⾃由报表⼯具、数据分析⼯具、数据挖掘⼯具和各类应⽤系统。
Hive 优缺点
Hive 优点
- 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写 MapReduce,减少开发人员的学习成本。
- Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
- Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
Hive 缺点
- Hive 的 HQL 表达能力有限,迭代式算法无法表达
- 数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却无法实现
- Hive 的效率比较低,Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
- Hive 调优比较困难,粒度较粗
Hive与传统数据库的对⽐
| 对比项 | Hive | 传统数据仓库 |
|---|---|---|
| 数据插入 | 支持批量导入 | 支持单条导入和批量导入 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 不支持 | 支持 |
| 分区列 | 支持 | 支持 |
| 执行延迟 | 高延迟 | 低延迟 |
| 扩展性 | 良好 | 有限 |
| 数据规模 | 大 | 小 |
Hive 架构原理
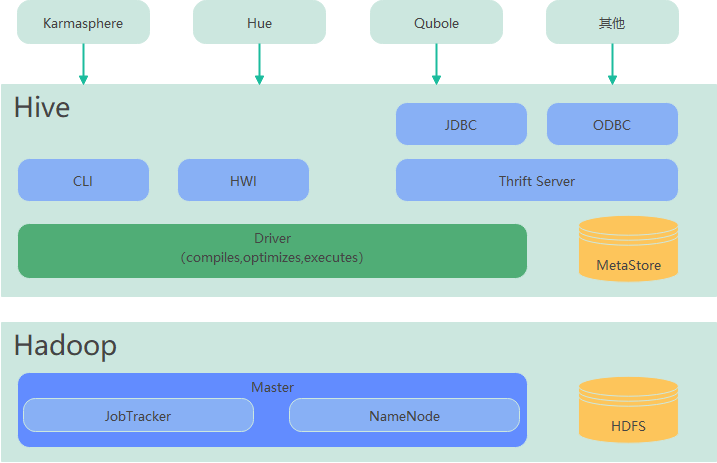
Hive 主要由以下模块组成:
1、用户接口模块
- 用户接口模块,含CLI、HWI、JDBC、ODBC、Thrift Server等,⽤来实现对Hive的访问
- CLI是Hive⾃带的命令行界⾯
- HWI是Hive的⼀个简单网页界面
- JDBC、ODBC以及Thrift Server可向⽤户提供进行编程的接口,其中Thrift Server是基于Thrift软件框架开发的,提供Hive的RPC通信接口
2、驱动模块
驱动模块(Driver),含编译器、优化器、执行器等,负责把HiveQL语句转换成⼀系列MR作业,所有命令和查询都会进⼊驱动模块,通过该模块的解析变异,对计算过程进行优化,然后按照指定的步骤执行
- 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
- 编译器(Physical Plan):将 AST 编译生成逻辑执行计划
- 优化器(Query Optimizer):对逻辑执行计划进行优化
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MapReduce /Spark
3、元数据模块
元数据存储模块(Metastore),是⼀个独⽴的关系型数据库通常与MySQL数据库连接后创建的⼀个MySQL实例,也可以是Hive⾃带的Derby数据库实例
- 主要保存表模式和其他系统元数据。如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等
4、存储计算模块
- 使用 HDFS 进行存储
- 使用 MapReduce 进行计算
5、界面访问
- 喜欢图形界⾯的⽤户,可采用几种典型的外部访问⼯具:Hue、Karmasphere、Qubole等。
Hive 工作原理
Hive 本质
将 HQL 转化成 MapReduce 程序
- Hive 处理的数据存储在 HDFS
- Hive 分析数据底层的实现是 MapReduce
- 执行程序运行在 Yarn 上
SQL查询转换成MR作业的过程
当 Hive 接收到⼀条 HQL 语句后,需要与 Hadoop 交互⼯作来完成该操作。HQL ⾸先进⼊驱动模块,由驱动模块中的编译器解析编译,并由优化器对该操作进⾏优化计算,然后交给执行器去执行。执行器通常启动⼀个或多个MR任务,有时也不启动(如 SELECT * FROM TB1,全表扫描,不存在投影和选择操作)
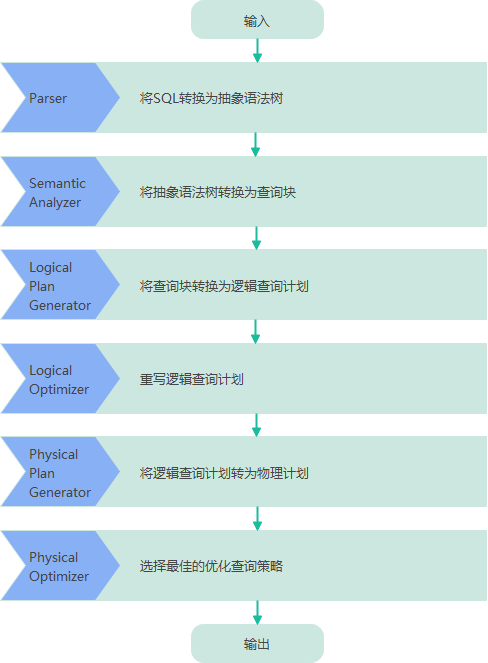
上图是 Hive 把 HQL 语句转化成 MR 任务进行执行的详细过程。
- 由驱动模块中的编译器–Antlr 语⾔识别工具,对用户输入的 SQL 语句记性词法和语法解析,将 HQL 语句转换成抽象语法树(AST Tree)的形式
- 遍历抽象语法树,转化成 QueryBlock 查询单元。因为 AST 结构复杂,不方便直接翻译成MR算法程序。其中 QueryBlock 是⼀条最基本的 SQL 语法组成单元,包括输入源、计算过程、和输入三个部分
- 遍历 QueryBlock ,⽣成 OperatorTree(操作树),OperatorTree 由很多逻辑操作符组成,如 TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator 和 ReduceSinkOperator 等。这些逻辑操作符可在Map、Reduce 阶段完成某⼀特定操作
- Hive 驱动模块中的逻辑优化器对 OperatorTree 进行优化,变换 OperatorTree 的形式,合并多余的操作符,减少 MR 任务数、以及 Shuffle 阶段的数据量
- 遍历优化后的 OperatorTree,根据 OperatorTree 中的逻辑操作符⽣成需要执行的 MR 任务
- 启动Hive驱动模块中的物理优化器,对⽣成的 MR 任务进行优化,⽣成最终的 MR 任务执行计划
- 最后,有 Hive 驱动模块中的执行器,对最终的 MR 任务执行输出。Hive 驱动模块中的执行器执行最终的 MR 任务时,Hive 本身不会生成 MR 算法程序。它通过⼀个表示 “Job执⾏计划” 的 XML 文件,来驱动内置的、原生的 Mapper 和 Reducer 模块。Hive 通过和 JobTracker 通信来初始化 MR 任务,而不需直接部署在 JobTracker 所在管理节点上执行。通常在大型集群中,会有专门的网关机构来部署 Hive 工具,这些网关机的作用主要是远程操作和管理节点上的 JobTracker 通信来执⾏任务。Hive 要处理的数据⽂件常存储在 HDFS 上,HDFS 由名称节点(NameNode)来管理。
注:上述 HiveSQL 转化为 MR 任务的过程只适用于 Hive3.0 以下版本。在 Hive3.0+ 版本中这个默认执行引擎被替换成了 Tez。
- Hive 简介
- Hive 优缺点
- Hive 架构原理
- Hive 工作原理